- Published on
The 4 Types of Data Backends
- Authors

- Name
- David Krevitt
- Link
- Data App Enthusiast
- Get in Touch
Table of contents
- What is a data backend?
- Example: SaaS embedded analytics
- Why build a data backend?
- Four data backend reference architectures
- Warehouse-first data backend
- App-first data backend
- Lake-first data backend
- Managed data backend
- The sidecar approach to migration
What is a data backend?
A data backend is purpose-built to serve analytics data to users of an application.
It comes into play in the event that data requirements (volume, freshness and cost) have outgrown the capabilities of the primary application backend (which exists to do less data-intensive tasks, like create and read users, accounts, etc).
For this reason, a data backend usually operates alongside (as a "sidecar" to) an application backend, and supplements its capabilities.
Example: SaaS embedded analytics
For this post, let's use embedded analytics within a SaaS application as an example in-app data experience in need of a data backend.
If you're unfamiliar with the definition of embedded analytics or vertical-specific data app, grab a quick refresher on in-app data experiences here.
For embedded analytics, events are generated from usage of the app or service, and the goal is to present aggregated usage metrics to end users.
At small data sizes, one could implement embedded analytics without any data backend at all (just using the application backend):
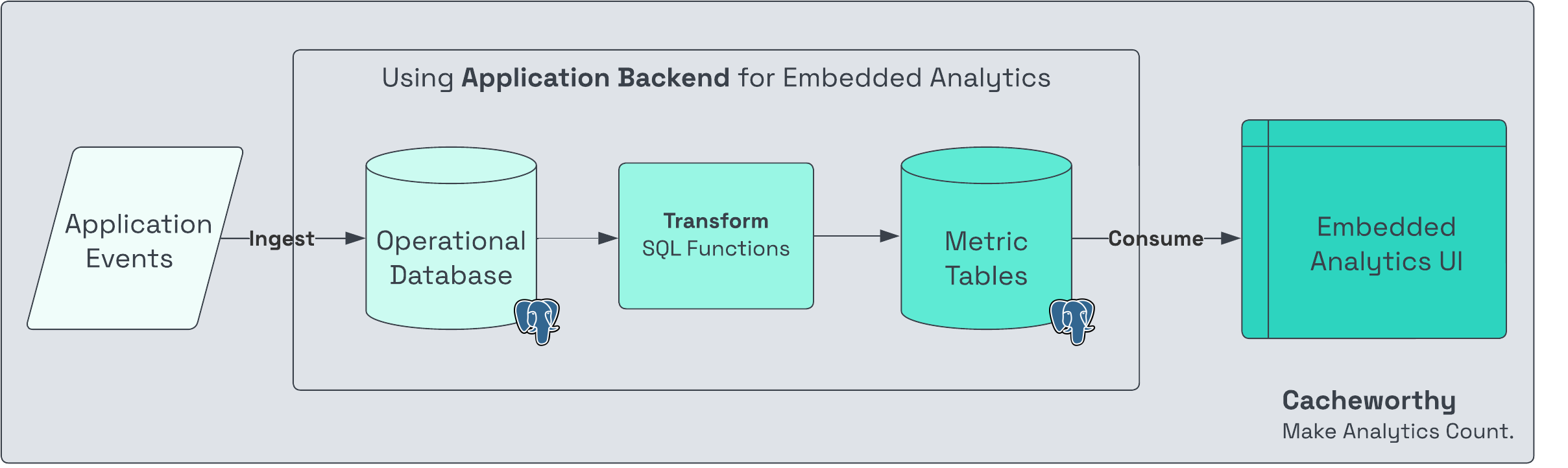
Application events are ingested into an operational database, transformed using SQL, cached as metrics in tables, and ultimately consumed by the frontend UI just like any database table would be.
Architectural choices in the box between ingestion + consumption define the data volumes + refresh frequencies (batch / streaming) that your data backend is capable of handling gracefully.
You'll need to either bring data to the application during ingestion + transformation, or bring the application to the data at consumption. This is how we classify data backend architectures below (app-first, warehouse-first, lake-first etc), based on whether we're bringing data to the app or vice-versa.
Why build a data backend?
But first, why bother doing this at all? We recommend building a data backend when (but rarely before) your primary application backend is unable to deliver the desired data experience (in terms of query latency, data size, etc) at reasonable expense.
When compared to an application database like Postgres, analytics infrastructure is designed to handle large data volumes at low cost.
On the other hand, for live querying of analytics datasets (to serve to end users), an application database will be significantly faster in terms of query response, and potentially cheaper.
Architecting a data backend is an exercise in navigating this cost vs latency tradeoff to make three decisions:
- How much pre-aggregation of datasets you need, in order to deliver performant queries to end users (max pre-aggregation = fastest user experience).
- How often must that pre-aggregation be run, on a spectrum of 1x/day batch to streaming (more frequent generally = more expensive).
- Where (in terms of data vs application backend) to execute that pre-aggregation in a cost-effective way, based on the answers to how much + how often.
Four data backend reference architectures
The ideal backend for your application will of course depend both on your requirements and your current architecture.
One can roughly break down fit like so:
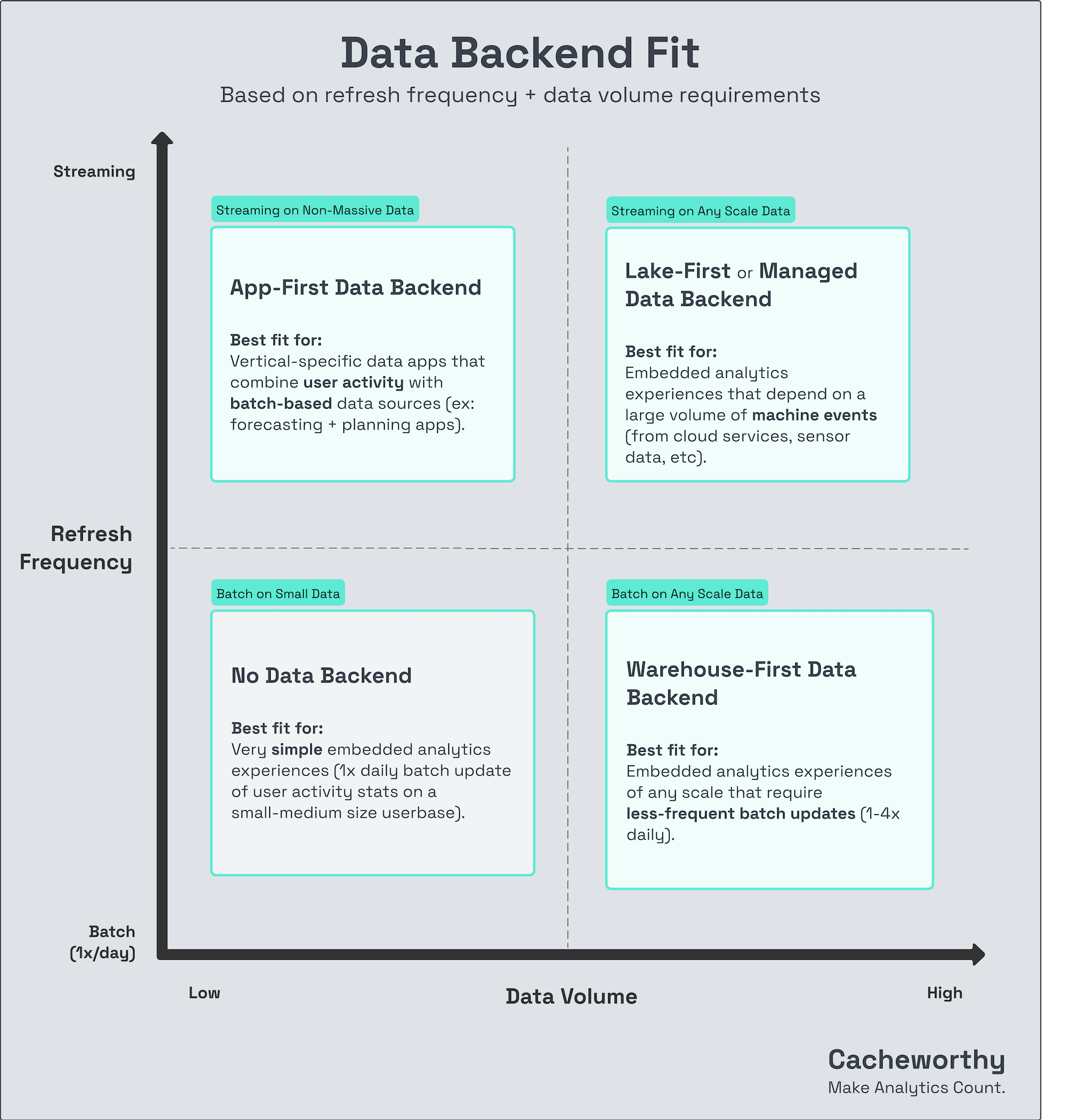
Let's get into the structure, pros and cons of those four data backend architectures.
Warehouse-first data backend
Serve data from your internal data warehouse (e.g. Snowflake) to your data application.
Involves pre-aggregating metrics in the warehouse, and then querying that data directly from the warehouse into the frontend.
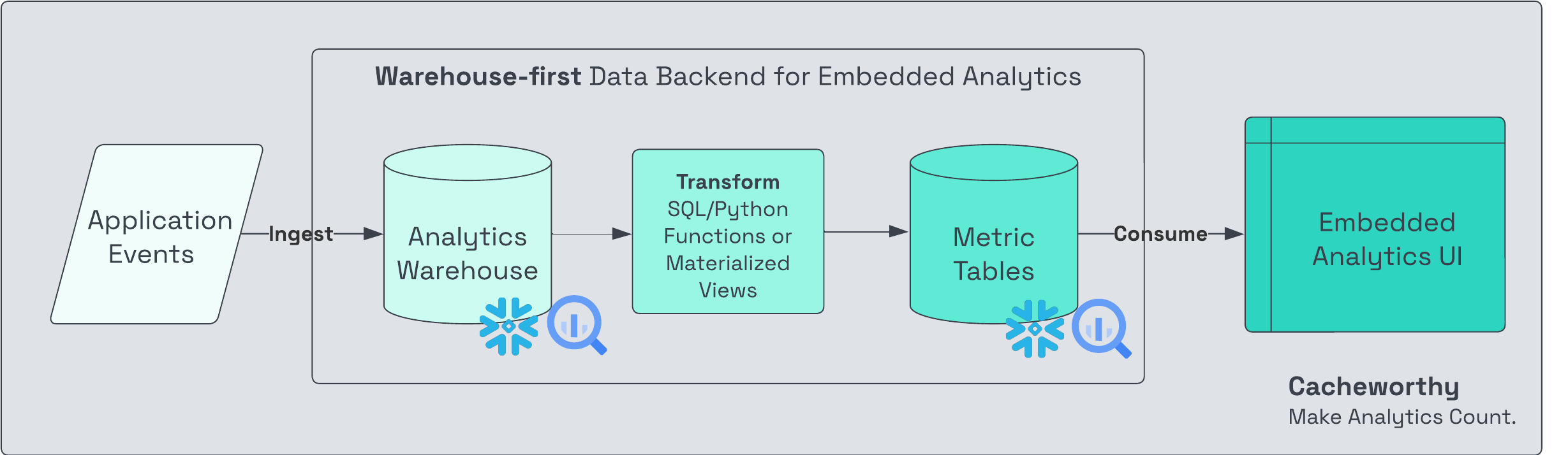
Pros of warehouse-first: Leverages familiar data tooling: if your internal data team has already spun up an analytics warehouse, you’re already halfway there.
Ease of sharing: most data platforms allow you to share datasets with external customers (or internal teams who don’t have permissions to access your entire warehouse), so you can validate outputs during app development.
Cons of warehouse-first: Cost: executing frequent data pre-aggregations on the warehouse (in preparation for application consumption) can be expensive, especially if your application requires extremely fresh data.
Not plug and play developer experience: presuming you're looking to avoid direct SQL querying during frontend development, which can introduce aggregation errors, you’ll likely want to develop your own API to serve specific query endpoints to your application.
--
Warehouse-first is a common place to start for vertical-specific data apps with reasonable data size + freshness requirements, especially if that app is to be used internally.
It’s not our first choice for serving real-time analytics, either embedded with a SaaS application or a vertical-specific data app, but warehouse platforms are certainly working on enhancing their streaming capabilities.
App-first data backend
Rather than querying a warehouse from the application, instead land pre-aggregated metrics directly in your operational database (e.g. Postgres).
Query analytics from there as you would any other application data to serve your frontend UI.
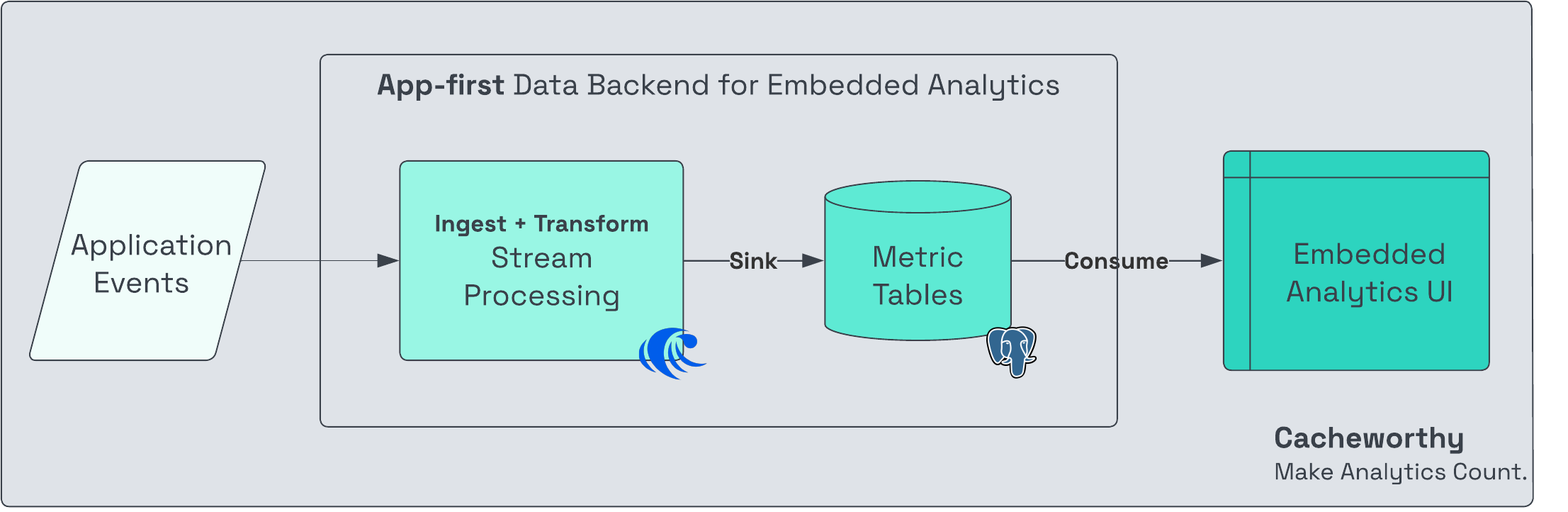
Pros of app-first: Fast: if you’re displaying pre-aggregated metrics or a reasonable small-medium number of line items, operational databases are extremely fast to query.
Leverages familiar frontend tooling: frontend engineers can use the same query APIs, authentication + tenant isolation patterns that they do for your primary application.
Large integration ecosystem: no matter what your data freshness requirements are (batch vs streaming), there’s likely tooling to meet those requirements that integrates natively with your application database.
Cons of app-first: Requires collaboration between frontend and backend: must clearly define what data needs to be pre-aggregated by the data backend for the frontend to function properly, which can lead to more back and forth collaboration than one would prefer.
Not suitable for truly large (e.g. event stream) datasets, which would require an additional analytics cache (likely a key-value store).
--
App-first is a great place to start for any data sidecar experience (embedded analytics or vertical-specific apps), assuming you have 1) a team that can directly collaborate between frontend and backend, and 2) reasonable data size requirements.
Lake-first data backend
Similar to the warehouse-first data backend, but using s3 for storage as opposed to the warehouse’s native storage.
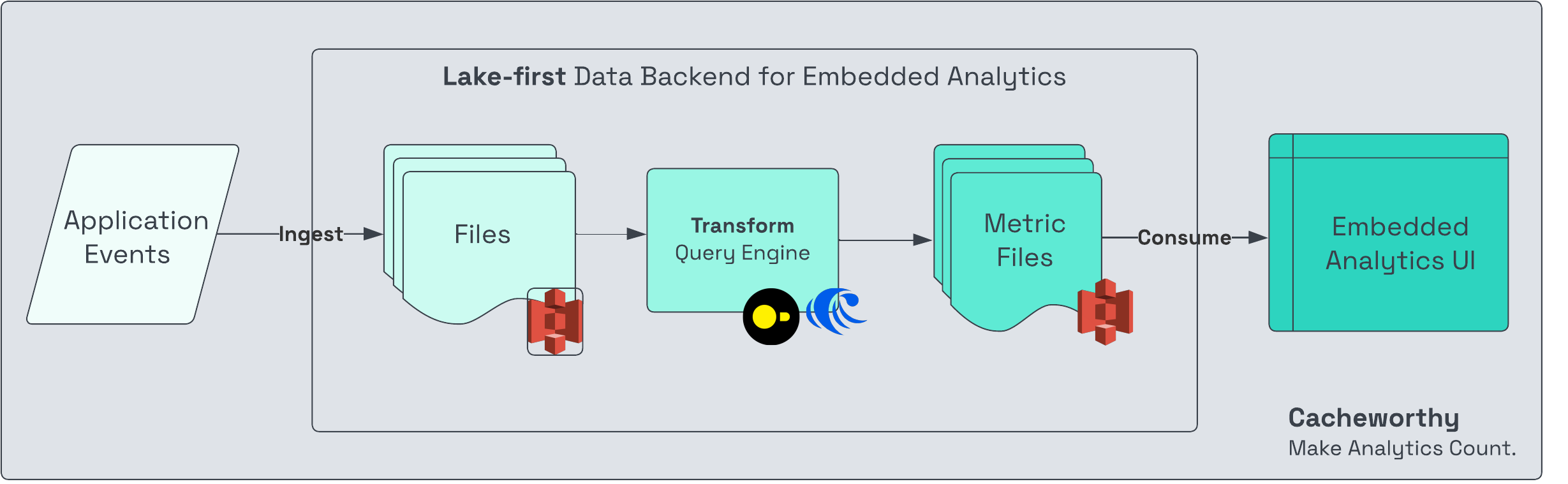
Pros of lake-first: Potentially lower cost than warehouse: by using an open source query engine like DuckDB on commodity compute (like AWS Lambda, EC2, or your own on-prem servers).
Flexible: Can use the ideal processing engine for the job (batch or streaming transformations), without having to first extract data from its source (the warehouse or application db), which can be costly and introduce another point of failure.
Cons of lake-first: Also not plug and play developer experience: Similar to warehouse-first, you’ll likely want to roll your own API for querying by the frontend.
--
Lake-first is a fit for applications that call for processing of large volumes of events, like embedded analytics for SaaS or some types of internal operational data apps.
For simple vertical-specific data apps that don’t require processing large volumes of events, we wouldn’t recommend a lake-based data backend as a starting point.
Managed data backend
Similar to a lake-based data backend, but with less setup + maintenance cost (the managed service owns that burden, and bills you for it over the course of your consumption).
You ingest your source data to the platform, define your data models (API endpoints) + desired latency (time-to-live of fresh data), and the platform serves your API for you.
Examples are Cube, Hasura, Patch, Propel, Tinybird and likely others that we’re missing.
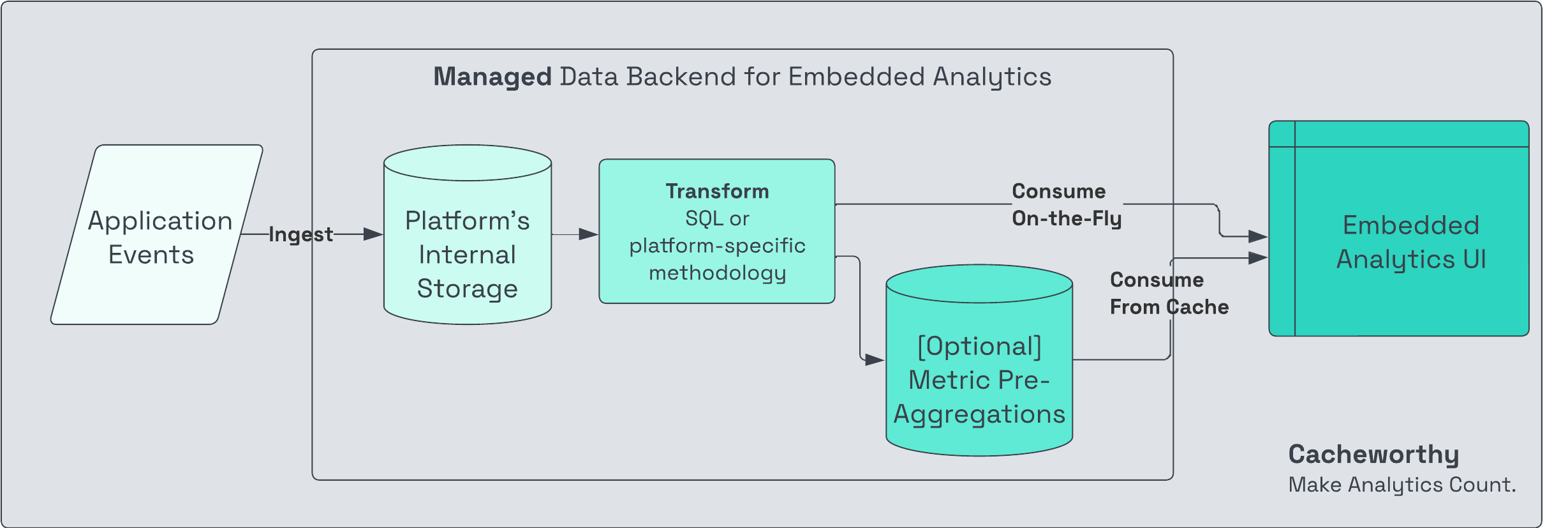
Pros of managed data backends: Simple rollout: Most of these platforms solve the data backend problem end-to-end, so your backend + frontend teams can align on one platform.
Low-latency querying and data refresh: If your customers require very fresh data or very fast querying, these platforms will get you there with minimal additional configuration or setup (just pay for what you need).
Cons of managed data backends: May require specialized data modeling: If your team is already comfortable with a data transformation framework like dbt, you may need to re-learn a new way of defining data models (Tinybird has “pipes,” each platform has their variant of choice).
May require paying for secondary storage: Again, if you already have a mature data warehouse or lake containing the data you’re looking to serve to customers, you’ll likely have to pay for egress to a platform’s proprietary storage in order to serve it to your app.
--
The fit for a managed data backend is very similar to lake-first: they're excellent for embedded analytics on top of events, whether that's in a SaaS app or internal operational tool.
For smaller / medium size analytics datasets within a vertical-specific app, they're potentially too much power for the job.
The sidecar approach to migration
Introducing a new layer to your stack, especially an entirely new backend, can be a daunting exercise.
Rather than attempting to migrate your application's entire analytics workload in one pass, we'd recommend taking things slow:
Pick one query or set of queries within your existing application, that your app backend either can't handle reliably, or does so with painful query times.
Peel that off, and spike a backend architecture that delivers the experience you're looking for - you might be surprised how quick of a win you'll be able to achieve, if you don't attempt to boil the ocean. Over time, you can migrate additional pre-aggregation workloads + query endpoints to that data backend.
--
If you're interested in digging deeper on this topic, reach out! We're actively doing research on data backend architectures and seeking to hone these recommendations.