- Published on
WTF is dbt?
- Authors

- Name
- David Krevitt
- Link
- Data App Enthusiast
- Get in Touch
Welcome to Cacheworthy
This post is a vestige of this blog's previous life as CIFL (2015 - 2023), which covered building analytics pipelines for internal reporting. When migrating to Cacheworthy and a focus on data applications, we found this post too helpful to remove - hope you enjoy it!
Curious about data applications? Meet Cacheworthy.With dbt + some SQL knowledge, you can transform yourself into an analytics engineer.
Doesn’t that have a nice ring to it?
dbt (formerly known as data build tool) is an open-source framework for running, testing and documenting SQL queries, that allows you to bring a software-engineering-style discipline to your data analysis work.
The primary discipline it brings is not repeating yourself, which makes it a wonderful tool if you're attempting to be "virtuously" lazy in your data work. Back when we did data consulting work, our team probably spent at least half of each day working in dbt.
Let's dig into what it does, what it replaces, and where it could fit into your workflow.
- Replacing the Saved Query
- ref(' ') will Change your Life
- SQL that Writes Itself
- dbt + Git
- Running SQL Queries on a Schedule
- Data Documentation the Lazy Way
- Are you Testing your Data?
- Portability Between Data Warehouses
- Getting Started with dbt
- dbt for Data Applications
Replacing the Saved Query
Every SQL query deserves a good home.
With dbt, your SQL queries are warmly tucked into a project’s folder structure, so you and your team always know where to find them:
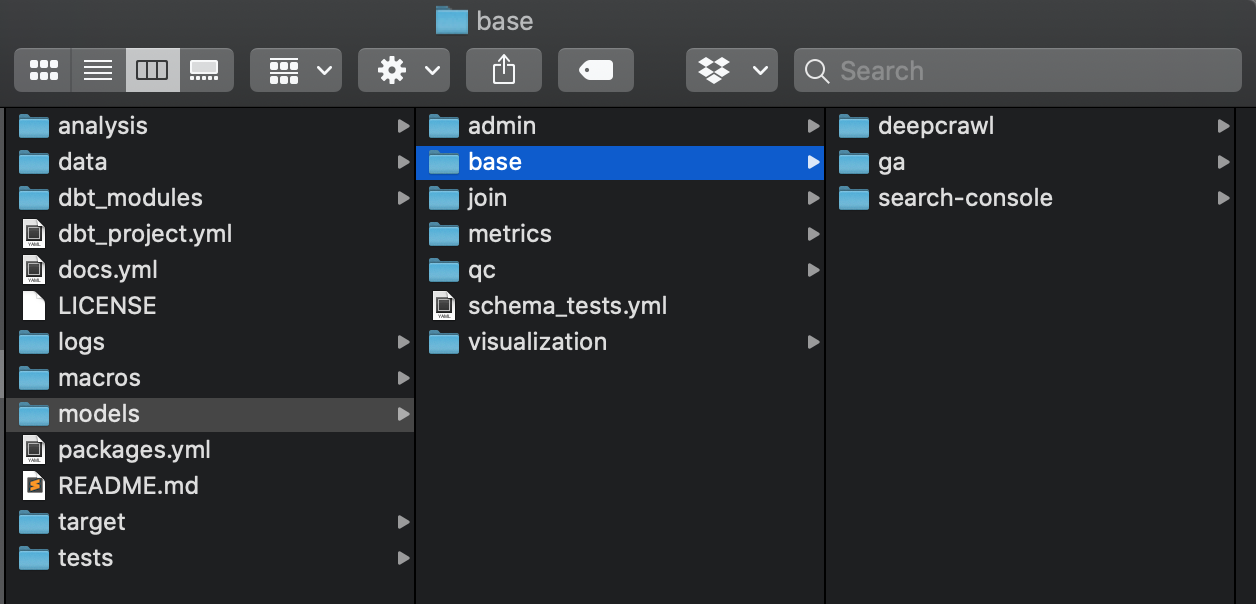
Any time you need to run them, they’re just a command away in your terminal:
dbt run
That single command takes the collection of SQL models in your dbt project, and refreshes them in your data warehouse.
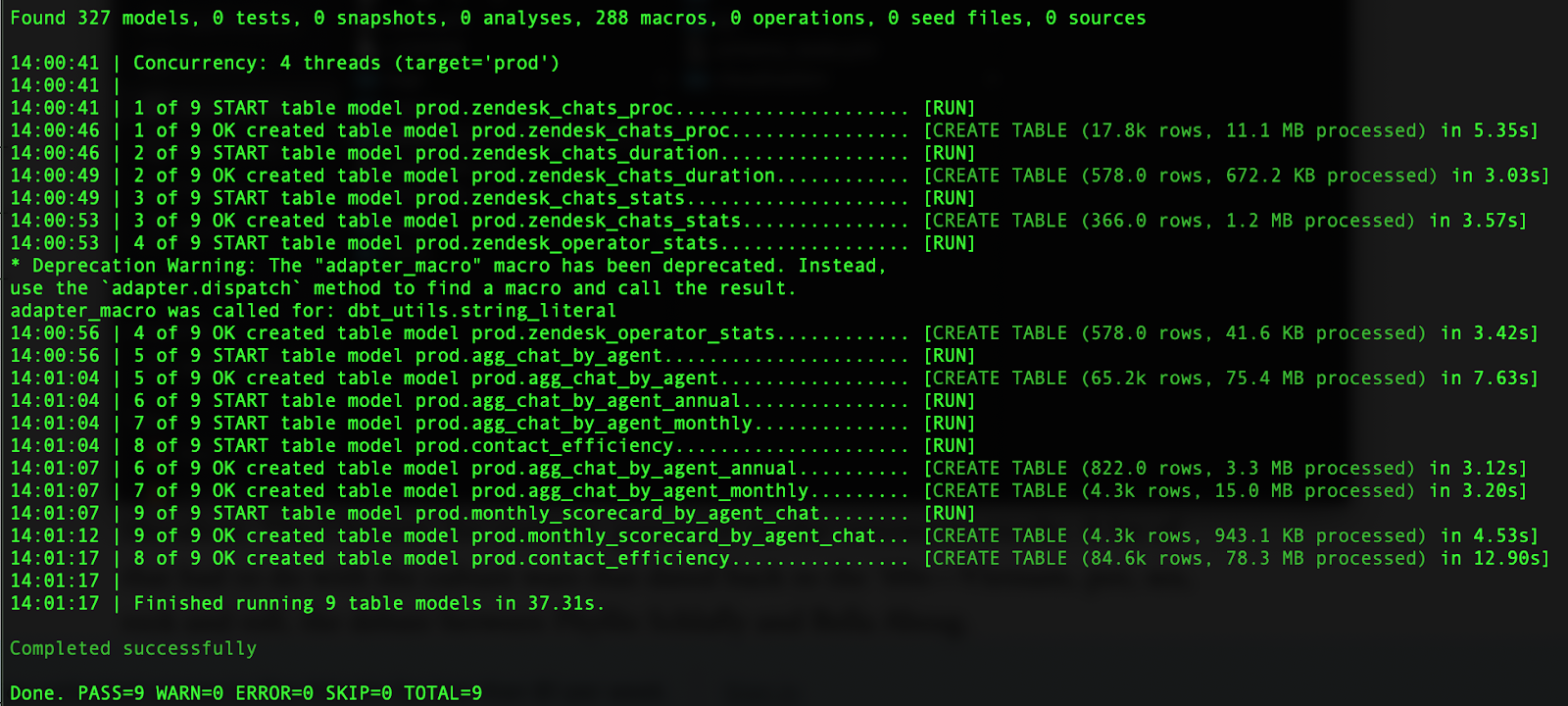
This is simple but effective.
It means no more saving SQL query snippets randomly on your desktop, like some kind of private treasure chest.
This scattering or disorganization of work is what kills data analysis projects - you do something once, and then forget how you did it the next time you get asked the same question.
dbt gives your analysis work a permanent home and a formal structure - a discipline, if you will.
ref(' ') will Change your Life
dbt allows you to reference other queries within your SQL queries by calling them via {{ ref(‘model name’) }}.
This keeps your queries very slimmed-down:

This way, every query does a single job. We build dbt project structures like a layer cake, composed of many interdependent layers, each doing their own job.
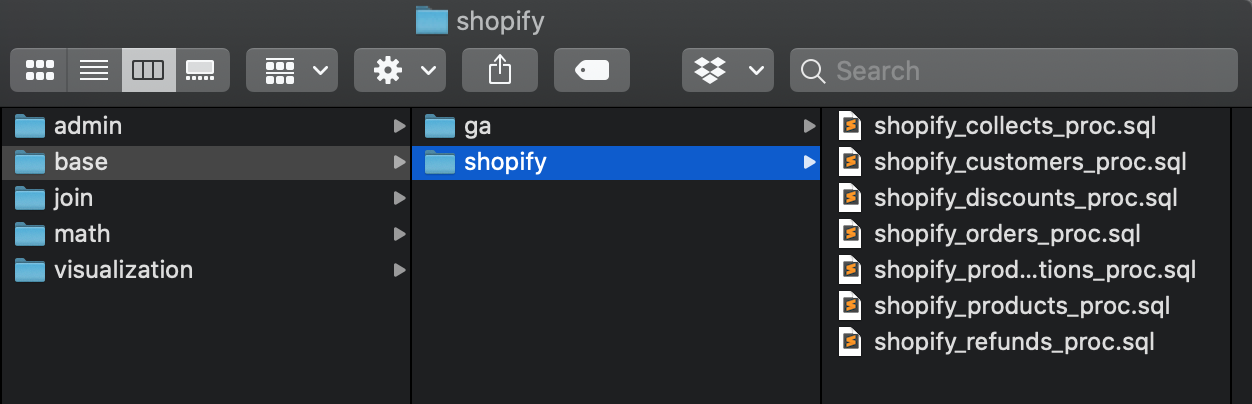
- /admin models store our pipeline’s settings + assumptions
- /base models dedupe and clean raw data
- /join models join together multiple /base tables
- /math models calculate metrics (churn, retention) and layer in any type of complex math (forecasting, etc)
- /visualization models prettify column names + get data into a presentation-ready format
This makes answering questions about *how* metrics are calculated very straightforward.
“How are we cleaning Google Analytics data?” Check out the base folder -> google-analytics.
“How are we calculating cohort retention rates?” Math -> cohort-analysis.
You get the picture - it makes your SQL queries very straightforward to navigate. Every team has their own data modeling approach (Kimball dimensional modeling, DataVault, etc) - no matter what that is, dbt allows your team to express their approach clearly in a folder + file structure.
SQL that Writes Itself
There are two ways that dbt takes the way you write SQL to the next level: macros + JINJA templating.
Macros
There can be a lot of grunt work when writing SQL queries.
Stuff like repeating CASE statements 15 times for different conditions:
CASE WHEN x = y THEN z
WHEN 2x = 2y THEN 2z
Blah blah blah - it can lead to carpal tunnel syndrome pretty quickly.
Another classic is UNIONing two tables, in which traditionally you’d have to repeat each table’s fields:
SELECT
Col1,
Col2,
null as Col3
FROM table1
UNION ALL
SELECT
Col1,
null as Col2,
Col3
FROM table2
With dbt, these SQL patterns can be repeated using macros.
The dbt team + contributors even maintain a handy list of key macros in the dbt_utils module, to accomplish so much grunt work we do everyday as analysts.
A couple of our favorite macros, that we use every day:
JINJA Templating
Programming gives us key frameworks for not repeating ourselves: FOR loops, IF-THEN statements, etc.
dbt makes embedding this programming logic in your SQL queries extremely simple, by allowing you to write SQL queries in JINJA notation.
This means that, instead of hardcoding your SQL queries, you can write queries that write themselves.
For example, back when we did data pipeline builds as a consultancy, we’d often store a list of Google Analytics conversion goal numbers for an agency’s clients:
- Client 1 uses goal #2 and #9
- Client 2 uses goal #4 and #11
The goal is to generate a single column,”goal completions,” for each client, from within a single query.
Before dbt, we’d write these queries by hand:
SELECT
goal2completions + goal9completions as goal_completions
FROM ga_table
With dbt, we generate the query dynamically, using JINJA templating:
{% set goals = get_column_values(table=ref('ga_conversions'), column='goal_name', max_records=50, filter_column='client_name', filter_value=account, filter_column_2='goal_name', filter_value_2='transaction' ) %}
SELECT
date,
channel_grouping,
sessions,
{% if goals != \[\] %}
{% for goal in goals %}
cast(goal{{goal}}completions as int64)
{% if not loop.last %} + {% endif %}
{% if loop.last %} as goal_completions, {% endif %}
{% endfor %}
{% else %}
0 as goal_completions
FROM {{ ref('ga_proc') }}
So instead of having to manually update a query anytime a client’s goal conversion numbers changed, we simply write a new value to the table, and the query writes itself.
Truly beautiful stuff for the lazy data analyst.
dbt + Git
With dbt + Git, you can actually write your data analysis like a software engineering team.
That means code reviews via Pull Requests, and bug tracking via Issues. No more editing SQL queries via long threads in Slack / Notion / email.
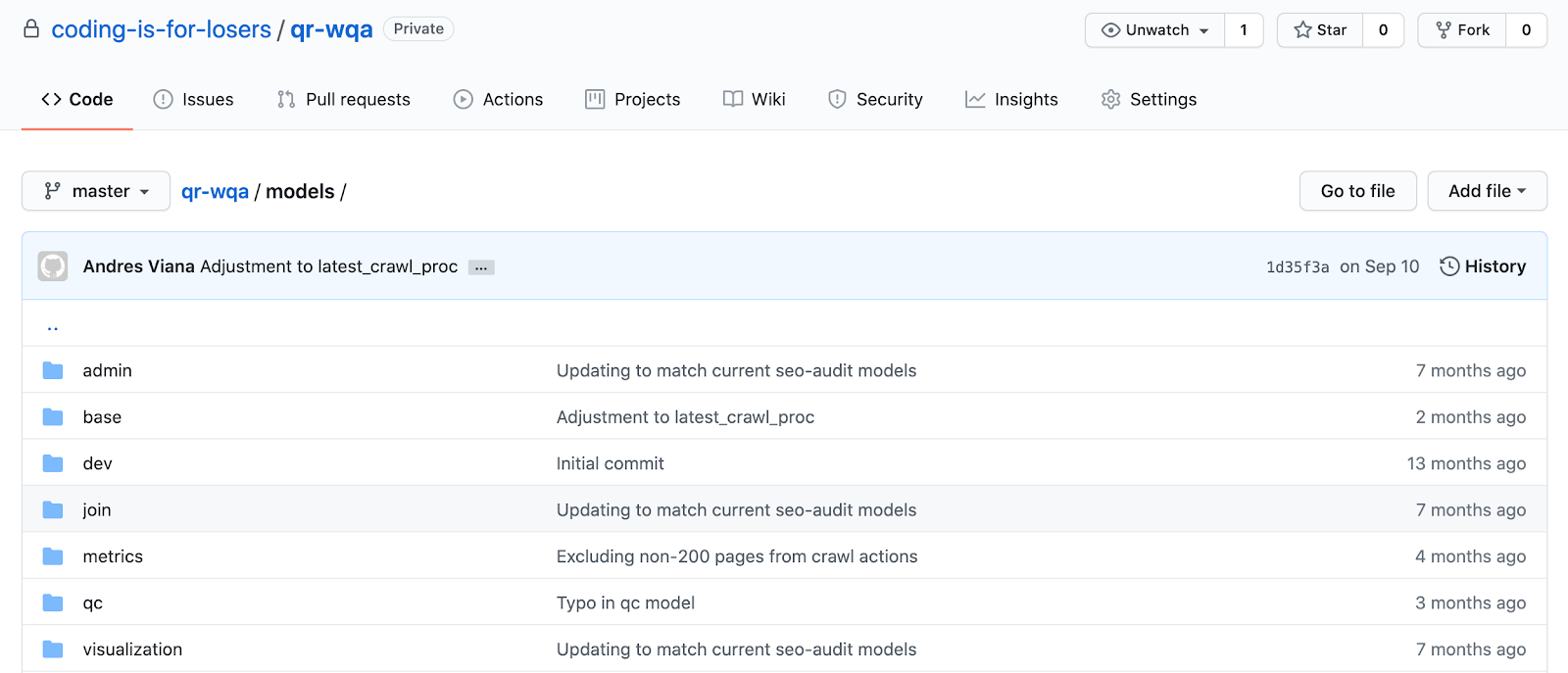
This has a few subtle + extremely beneficial effects:
People take SQL queries more seriously, and give them the space + time they need to develop. Hurry + interruption are the twin enemies of good data work.
Queries are written once, and then available to use by anyone else on your team. If used properly, this means you never write the same query twice.
This also means that you write higher quality SQL, because it’ll be reused by other people. This puts a healthy upward pressure on your code quality.
Running SQL Queries on a Schedule
“When was this data last refreshed?” It’s the perpetual question we receive as data analysts.
With dbt, the answer is never in doubt.
dbt Labs (formerly known as Fishtown Analytics, the team behind dbt) offers dbt Cloud, a hosted platform for running dbt projects on a schedule.
dbt Cloud includes a clean interface for viewing the status of your various model runs, test results and (my favorite feature) programmatically-generated documentation.
It’s free for a single developer account, and $50 per seat/month after that.
Data Documentation the Lazy Way
“How was this metric calculated? What raw table does this field come from?”
These questions should never have to be answered more than once - these are why documentation exists. But documentation has two key problems:
Freshness
If you have to update it manually, it’ll never stay current.
Anyone who tells you that their manually-written data documentation is 100% fresh, probably also has an island in the Maldives to sell you.
Location
Documentation usually lives somewhere other than where you use your data - can't spell documentation without document, and generally we don't analyze data in documents.
We need documentation where we consume data: in our case mostly in the BigQuery console, or Google Data Studio dashboards.
dbt solves both of these problems for us:
The
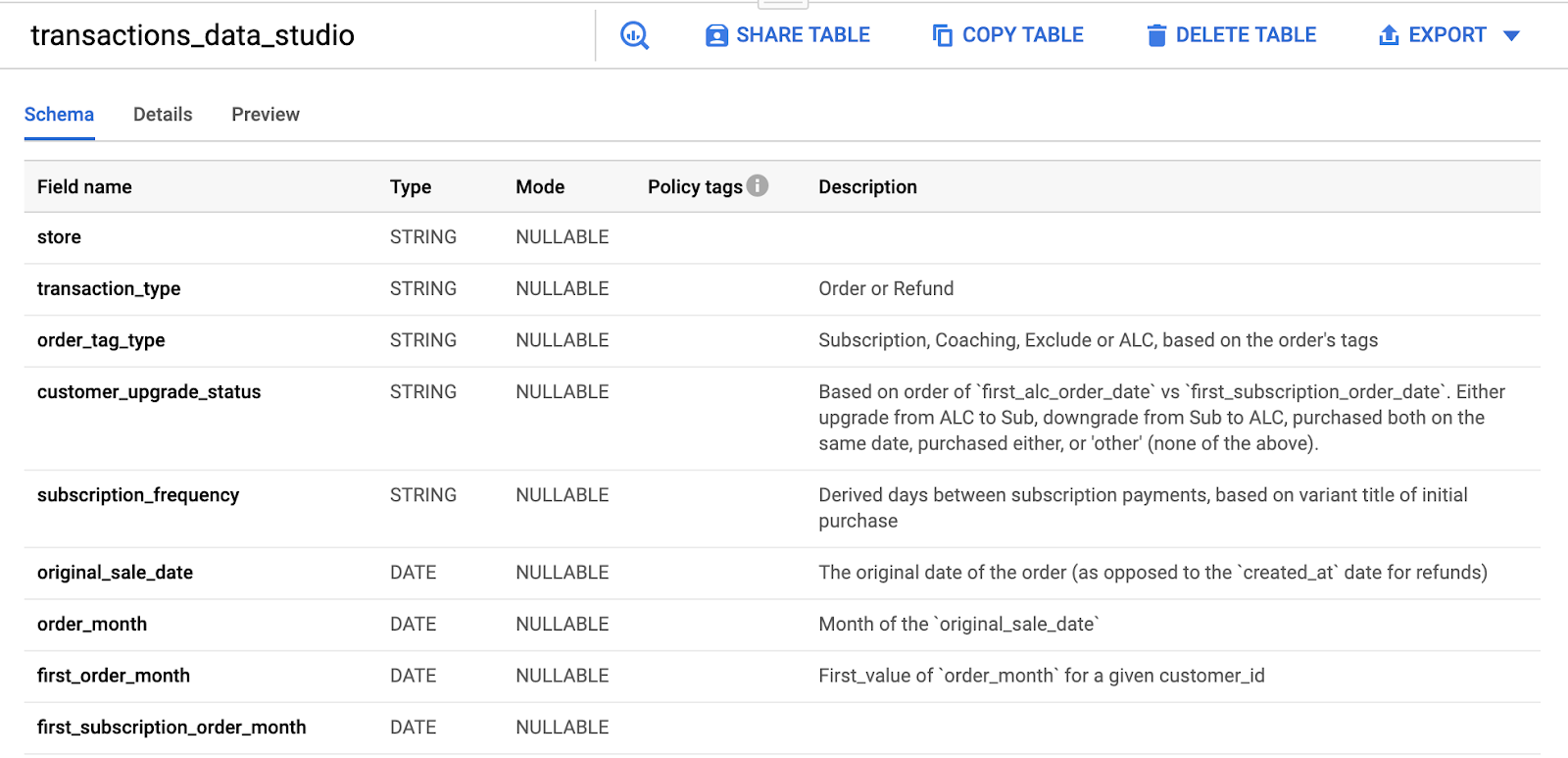
dbt docscommand programmatically generates a visual dependency graph out of your set of SQL models, which allows you to surf your SQL model dependencies from one single page.dbt allows you to set table + column-level descriptions from a single .yml file in your dbt project.
These definitions flow through directly into the BigQuery console:
As well as any Data Studio data source:
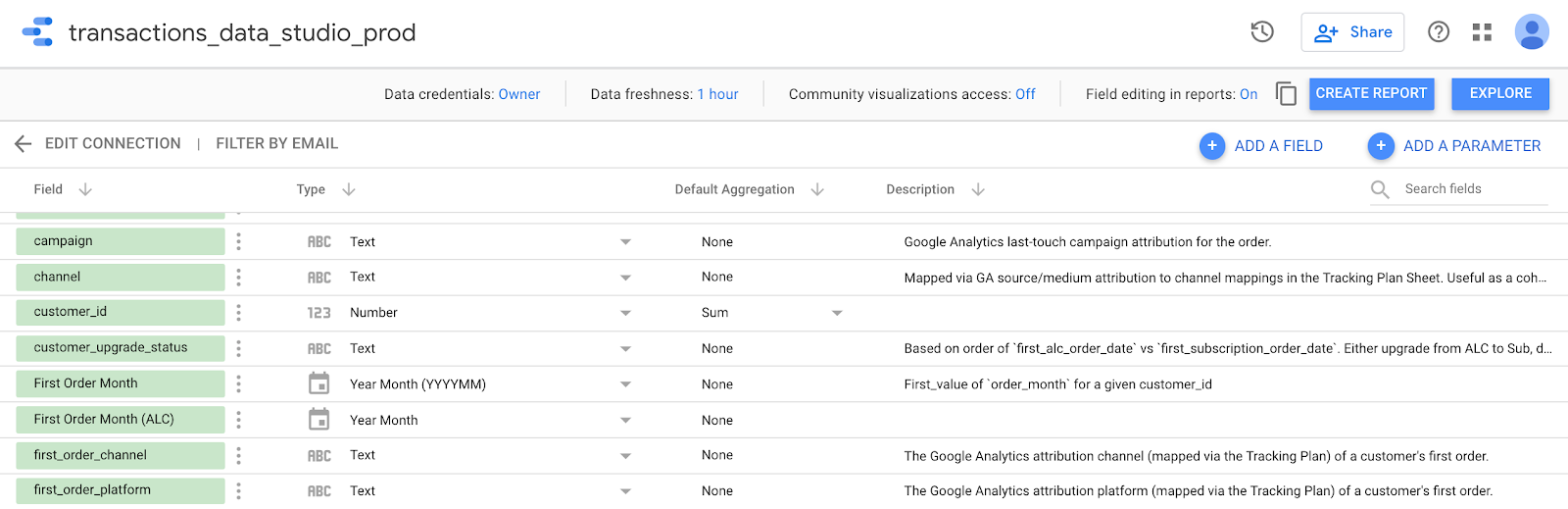
Other data warehouses (Snowflake, etc) or data visualization tools (Looker, etc) ingest these table + column descriptions in similar ways. So you can write field definitions one time, and run them anywhere.
Are you Testing your Data?
When an analytics workflow goes perfectly, your work is invisible - it helps people make decisions, without having to know everything about how it came together.
Testing helps your work stay invisible, by avoiding data quality issue that could spoil trust in it.
dbt covers this flank nicely, with automated schema + data testing.
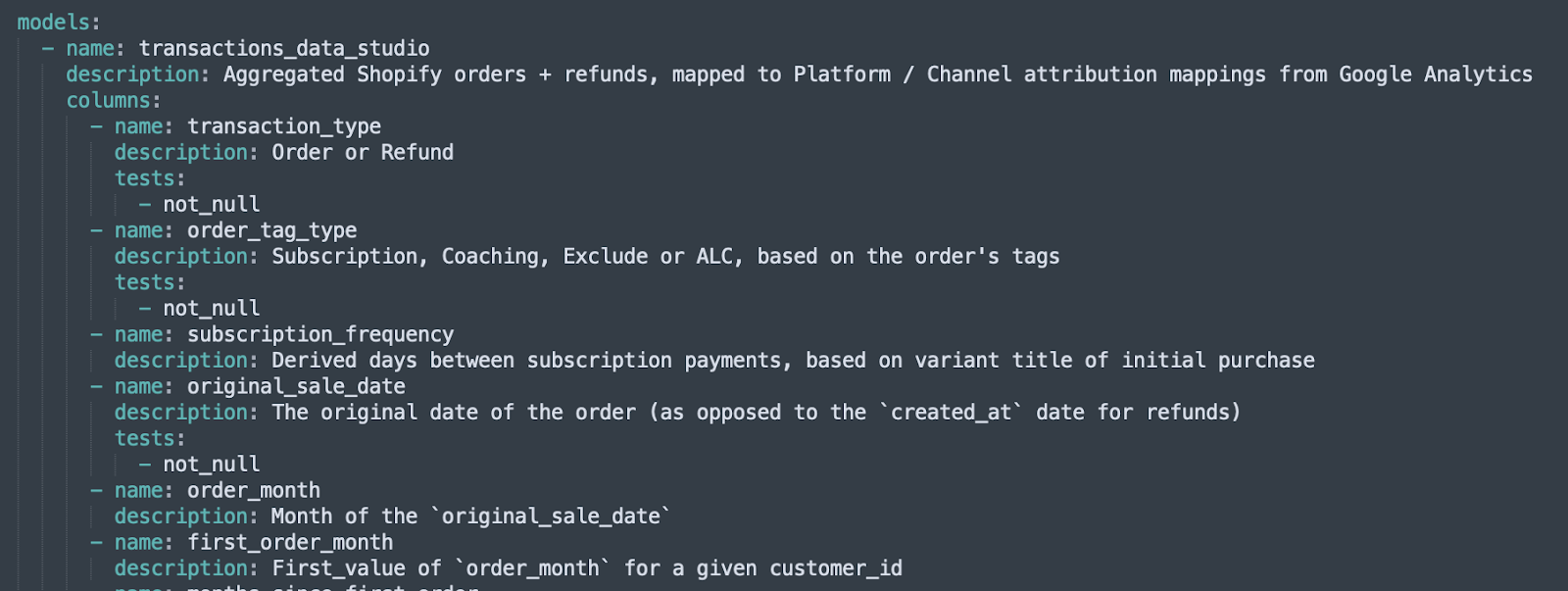
If a column shouldn’t ever be null, but has somehow been nullified, dbt tests will flag that for you.
If your JOIN is just a bit too generous, and results in rows being duped, dbt tests will flag that for you.
You can basically write any SQL query as a test, and dbt will flag a warning or error for you.
Portability Between Data Warehouses
Each flavor of data warehouse - BigQuery, Snowflake, or a regular old PostgreSQL database - has its own, slightly different SQL syntax.
That means, if you migrate from BigQuery to Snowflake, or from Redshift to BigQuery, you often have to rewrite your SQL queries to accommodate these nuances.
BUT - dbt takes care of that abstraction for you, as it includes adapters for all of the common data warehouse platforms.
You can, with limited modification, port your dbt models to run on a different data warehouse.
And, since dbt is open-source, you’re free to contribute your own adapters (as folks have done for databases like MS SQL, which are less commonly-used as analytics warehouses).
This makes life much easier for anyone working across warehouses - whether that's at a consultancy where you work with various client stacks, or in-house at an organization who are work on multiple warehouses.
Getting Started with dbt
If you’re ready to dive into implementing dbt on your team, there are two ways we can help:
- Our free course, Getting Started with BigQuery SQL, includes an intro to data modeling in dbt
- Our flagship course on data pipelining, Build your Data Agency, which includes a deeper dive into building your entire data analysis workflow around dbt
dbt for Data Applications
At Cacheworthy, we're exploring how organizations can leverage dbt for data modeling within data applications, using the same toolbelt that one might use for building internal data pipelines.
Stay tuned for more on that!